Newsroom





In the complicated acoustic application scenarios, speech signals tend to be contaminated by environmental noise and room reverberation. This may influence robust automatic speech recognition (ASR) and speech communication.
Deep learning-based monaural speech enhancement methods could effectively suppress the distortion components. However, it is difficult for them to implement in current resource-limited micro-controllers due to the large number of trainable parameters and high computational complexity.
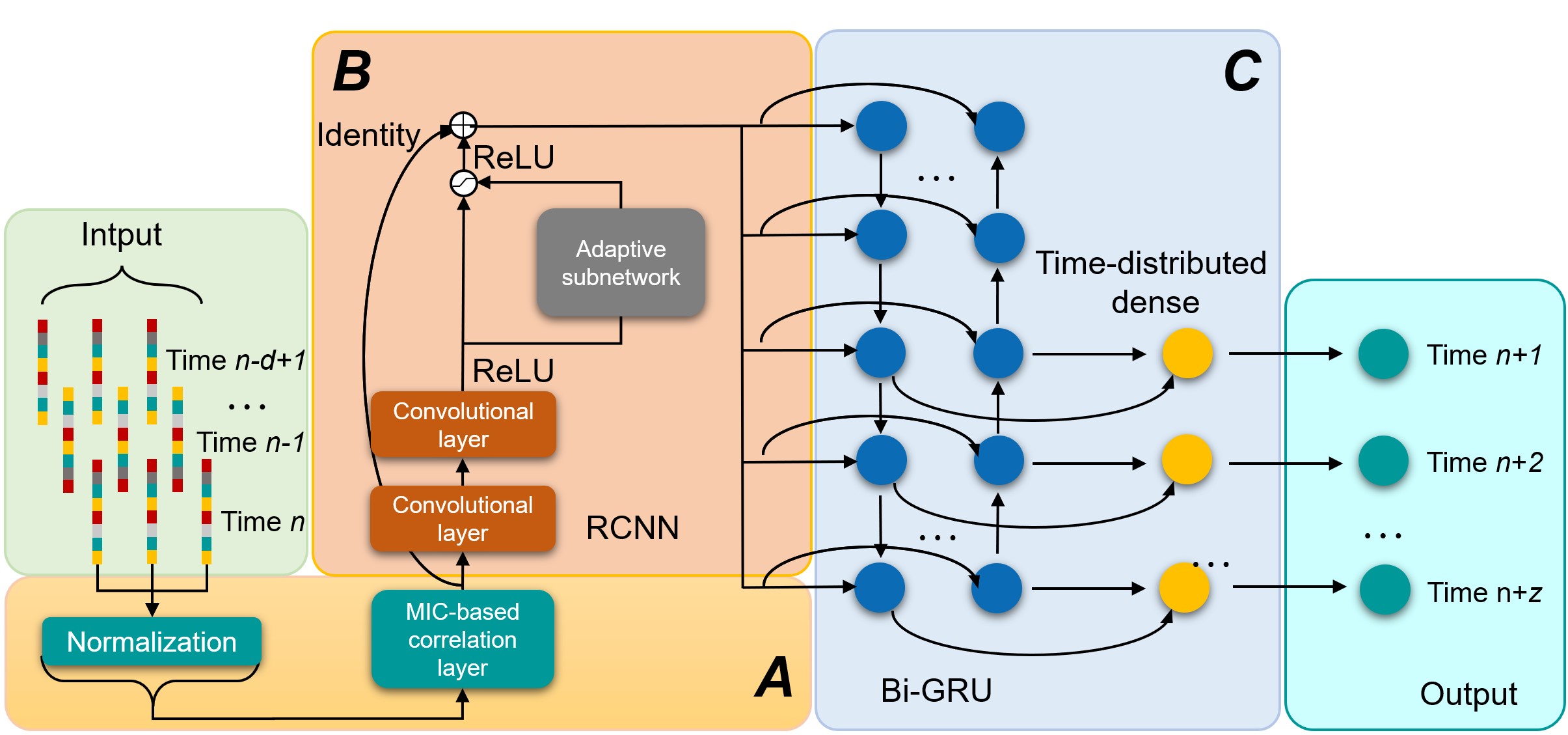
Recently, researchers from the Institute of Acoustics of the Chinese Academy of Sciences (IACAS) proposed a type of monaural progressive speech enhancement approach based on convolutional recurrent neural network (CRNN). It significantly decreased the trainable parameters and the computational complexity while sustaining the performance.
Based on CRNN, researchers decomposed the whole enhanced process into multiple stages. Then they modeled each of the stage with a lightweight module and improved the signal-to-noise ratio (SNR) of the training target compared with original noisy speech.
As a consequence, the estimation outputs in previous stages could be exploited as the prior information to progressively boost the results in subsequent stages.
In addition, the researchers reused long short-term memory (LSTM) module in different stages, which notably decreased the trainable parameters.
Experimental results showed that when the number of the stages was 3, the performance was similar to the complicated CRNN model and could be further improved with the increase of the number of stages.
This work could be utilized for noise suppression and speech information retrieval in the source-limited micro-controllers.
The research, published in Applied Acoustics, was supported by the National Natural Science Foundation of China.

Algorithm system flowchart (Image by IACAS)